Growing an enterprise places massive stress on foundational systems, making infrastructure planning a critical factor in long-term success. When data centers run hot, transport networks face gridlock, or supply chains bottleneck, the root cause is rarely a lack of raw capital. Instead, it is usually a mismatch between expanding demand and static capacity. As capacity planners, operations researchers, and data scientists, we view infrastructure not as fixed physical properties, but as dynamic, mathematical state machines. Our job is to project future needs so businesses can scale seamlessly without over-spending on premature upgrades or suffering catastrophic outages.
To scale successfully, an organization must manage infrastructure planning through a precise operational lens. We focus heavily on three core operational metrics: maximizing throughput, reducing cycle time, and minimizing scrap rate. Throughput represents the actual volume of successful work or data flowing through our architecture per unit of time. Cycle time measures the end-to-end duration required for a single unit of work to clear the system. Scrap rate represents the percentage of computational, physical, or logistical resources wasted due to failures, drops, or inefficiencies. Balancing these three levers requires moving away from static forecasting and adopting rigorous scenario planning for growth.
1. The Core Equation Linking Growth to Operational Assets
Traditional capacity management relies on historical linear regression, assuming that tomorrow will look exactly like yesterday, just slightly larger. This approach often fails because physical and digital infrastructure systems scale non-linearly. When load doubles, a system’s queue lengths, wait times, and failure rates do not simply double; they tend to explode exponentially as resources reach saturation points. By applying operations research models, we simulate complex future states to understand exactly where asset constraints will occur before they impact live environments.
Maximizing throughput is our first line of defense against growth bottlenecks. When we plan infrastructure scenarios, we evaluate the system’s maximum processing capacity under variable loads. If a fulfillment hub or a cloud computing cluster cannot maintain its output rate as incoming volume surges, the entire enterprise stalls. To prevent this, data scientists build stochastic simulation models that expose hidden operational limits. These models allow us to see how a ten percent increase in transactional volume might trigger a fifty percent decline in system performance, helping us target infrastructure investments where they will provide the greatest return.
2. Attacking Latency and Eliminating the Micro-Stop Thieves
Cycle time is the ultimate measure of system health and responsiveness. In a world focused on rapid delivery, any increase in the time it takes to process a request or move an item directly reduces profitability. When infrastructure capacity becomes strained, units of work spend more time waiting in queues than actually being processed. This accumulation of work-in-progress inventory inflates costs and ties up valuable operational capital.
Scenario planning for growth requires our engineering teams to systematically identify and eliminate these latency spikes. We analyze data logs to isolate tiny, frequent operational pauses, often called micro-stops. These minor disruptions, such as brief server timeouts or minor mechanical misalignments on a sorting line, are frequently missed by high-level performance metrics. However, when multiplied across millions of operations, they drastically increase average cycle times. By modernizing legacy architecture and optimizing process flows, we ensure that work moves through the system smoothly and continuously.
3. Eradicating Wasted Capacity and the Hidden Toll of Scrap Rate
Scrap rate is often considered a traditional manufacturing metric, but it applies equally to digital and modern logisitical infrastructure. In cloud computing, scrap manifests as dropped data packets, failed API calls, and wasted processing cycles that require expensive rollbacks. In logistics, it appears as spoiled inventory, misrouted shipments, or underutilized cargo space. Every time a system produces an error or fails to execute a task correctly, it consumes valuable cycle time and forces the infrastructure to work twice as hard to deliver a single successful output.
Total Capacity Utilized = Productive Throughput + Scrap (Wasted Cycles)
Minimizing the scrap rate is a highly effective way to unlock hidden infrastructure capacity without buying new equipment. When a system operates with high defect rates, it wastes energy and hardware cycles on unusable results. Our data science teams analyze historical error logs to find the root causes of these operational failures. By implementing stricter quality controls and automated error recovery, we ensure that every unit of energy or computing power directly supports productive output.
4. Building Scalable Infrastructures Through Stochastic Modeling
To make scenario planning for growth truly actionable, we must account for real-world volatility. Deterministic planning models assume that processing times and customer demands are perfectly predictable, which can lead to severe under-provisioning. Operations research analysts use stochastic modeling and Monte Carlo simulations to inject realistic randomness into our capacity models. This approach allows us to test how infrastructure behaves during sudden demand spikes, volatile supplier timelines, and unexpected hardware failures.
This probabilistic modeling approach shifts the conversation from guessing a single future to preparing for a range of potential outcomes. We evaluate how throughput holds up when multiple negative events happen simultaneously, such as a major network outage occurring during a seasonal peak in demand. These simulations help us establish clear operational triggers, allowing leadership to see exactly when to deploy capital for infrastructure upgrades before performance degrades.
5. Balancing Asset Governance with Financial Risk Mitigation
Infrastructure planning is fundamentally a balance between operational readiness and financial discipline. Over-provisioning infrastructure creates idle capacity that drains capital and lowers return on assets. Conversely, under-provisioning causes service degradation, missed customer agreements, and lost revenue. Effective asset governance provides the framework needed to balance these competing priorities by using real-time data to guide major investment decisions.
We use advanced asset governance models to treat infrastructure investments as options rather than fixed obligations. By designing modular systems, organizations can expand capacity in small, incremental steps as real-world demand matches our growth triggers. This flexible approach protects the company’s capital while ensuring the infrastructure can scale rapidly when market opportunities arise.
6. Real-World Applications: Optimizing Digital and Physical Networks
Looking at a large-scale e-commerce fulfillment network demonstrates how these principles apply in practice. When transaction volume grows rapidly, processing centers face severe space constraints, causing cycle times to climb. By applying scenario planning, we can model various automated sorting layouts to maximize throughput. This simulation data allows us to optimize package routing, keeping utilization high and ensuring fulfillment speeds stay consistent during peak shopping seasons.
We see the exact same dynamics at play within cloud computing architectures. When a digital application scales up to handle millions of new global users, database performance can degrade, leading to high scrap rates in the form of failed user requests. Capacity engineers use these operational insights to deploy automated scaling policies and distributed caching layers. These targeted adjustments isolate database pressure, lower cycle times, and ensure the system maintains high throughput without requiring a complete, costly rewrite of the core infrastructure.
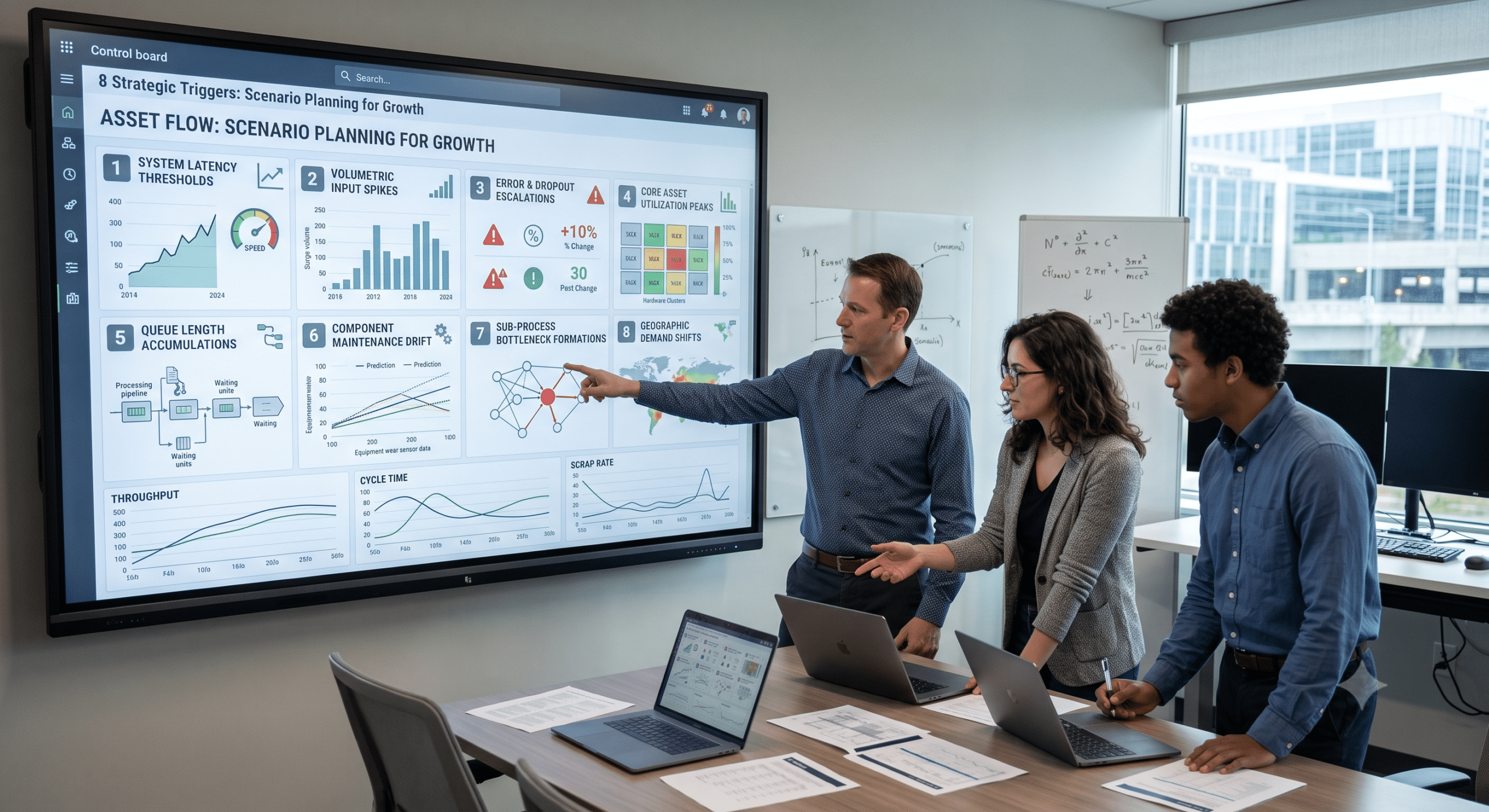
7. The Eight Essential Triggers for Future-Proof Growth
To execute this strategy cleanly, we have structured an operational checklist built around eight critical triggers that every capacity planner and data scientist must monitor.
-
System Latency Thresholds: When average cycle times consistently exceed defined baselines during normal operations, it signals that current infrastructure is reaching its natural efficiency limit.
-
Volumetric Input Spikes: Tracking consistent upward trends in raw demand allows planners to scale up resource availability before those surges cause system wider backlogs.
-
Error and Dropout Escalations: A sharp increase in scrap rate or failed requests indicates that the existing infrastructure can no longer handle the processing complexity under load.
-
Core Asset Utilization Peaks: When primary components run near ninety percent capacity for extended periods, the system loses the flexibility needed to absorb sudden operational spikes.
-
Queue Length Accumulations: Persistent backlogs of work-in-progress inventory mean processing steps are unbalanced, requiring immediate localized optimizations.
-
Component Maintenance Drift: Increased frequency of hardware or software micro-stops indicates that assets are degrading, which will quickly lead to lost throughput if left unaddressed.
-
Sub-process Bottleneck Formations: Identifying the single slowest step in an operational chain ensures that capital investments are directed where they will actually improve total system output.
-
Geographic Demand Shifts: Changes in where users or customers are located require shifting infrastructure assets closer to those end-points to keep delivery times minimal.
8. Sustaining Peak Operational Efficiency Over the Long Term
True infrastructure resilience is an ongoing process of monitoring, modeling, and iterative improvement. As business goals evolve and market dynamics shift, our scenario models must adapt to match those new realities. Continuous automated feedback loops feed live operational metrics back into our data science models, steadily improving their predictive accuracy over time.
By focusing on throughput, cycle time, and scrap rate, organizations can transform infrastructure planning from a cost center into a clear competitive advantage. Businesses no longer have to guess at their future needs or react blindly to sudden operational crises. Instead, data-driven scenario planning gives leadership the clarity and confidence required to scale up operations smoothly, efficiently, and profitably.
Frequently Asked Questions
What is the primary difference between traditional capacity forecasting and scenario planning for growth?
Traditional capacity forecasting uses historical data to predict a single, linear trajectory for future resource needs. Scenario planning for growth acknowledges that future demand is uncertain and models multiple distinct future states, allowing organizations to build flexible infrastructure strategies that can adapt to different growth rates.
How do changes in cycle time affect overall system throughput?
Cycle time and throughput are closely linked through operational queues. When cycle time increases due to friction or resource constraints, units of work remain in the system longer, which creates backlogs, starves downstream processes, and ultimately reduces the total throughput of the infrastructure.
Why is reducing the scrap rate considered an alternative to buying new infrastructure?
Scrap rate measures wasted operational capacity, such as defective products or dropped computational tasks. By lowering this waste, you convert unproductive resource consumption back into usable capacity, allowing the existing infrastructure to handle higher volumes of successful work without requiring additional capital investments.
What role do data scientists play in the infrastructure asset governance process?
Data scientists build the stochastic models and predictive simulations that translate raw operational logs into clear future capacity forecasts. Their analysis exposes hidden bottlenecks and defines the precise performance triggers that leadership needs to make timely, cost-effective infrastructure investments.
References and Further Reading
-
For an in-depth look at how enterprises navigate long-term operational uncertainty and structural resilience, review the comprehensive guide on Strategic Scenario Planning Frameworks by SAP.
-
To learn more about the tactical steps required to build adaptable forecasting models and coordinate cross-functional operations teams, consult the strategic breakdown on Operational Scenario Planning and Modeling by NetSuite.